What is Apache XTable (formerly OneTable) — Interoperability for Apache Hudi, Iceberg & Delta Lake
Apache Hudi, Iceberg, and Delta Lake provide a table-like abstraction on top of the native file formats like Parquet by serving as a metadata layer and providing necessary primitives for compute engines to interact with the storage. While these formats have enabled organizations to store data in an independent open tier, decoupled from compute, the decision to adopt one particular format is critical. The question is — ‘Is there another way?’
TL;DR: XTable (previously OneTable) provides a seamless way to interoperate between different table formats by translating table format metadata.

Phase 1
To give a bit of background, the lakehouse architecture evolved in response to a critical requirement: the desire to combine the data management advantages of warehouses (OLAP databases) with the enhanced scalability and cost-effectiveness characteristic of data lakes (S3, Azure, Hadoop). A common trend organizations follow to deal with various analytical workloads, such as BI and ML is adopting a two-tier architectural strategy, using both data warehouses and cloud data lakes. While this approach seemed reasonable, it soon led to a proliferation of issues such as unmanageable data copies, higher maintenance costs, and delays in insights, among others.

At its core, the lakehouse architecture enables storing data in open file and table formats such as Parquet, Apache Hudi/Iceberg, and Delta Lake. It offers transactional capabilities (with guarantees) and data management features like compaction, clustering, and Z-ordering. The open and independent data tier (table format) involves bringing the necessary compute engine to the data for the appropriate workload, not the other way around. So, if your workload is distributed ETL, you can use Spark, or for stream processing, Flink can seamlessly consume the data from the table formats. Many organizations have adopted this new form of architecture today to leverage the discussed benefits, powering their workloads.
The table formats in a lakehouse architecture have empowered organizations to be cost-efficient with the flexibility to store data in open formats in their owned storage systems (e.g., S3 buckets). However, when it comes down to the table formats, there are three options. Each format has rich features that may cater to different use cases. For example, Hudi works great for update-heavy and incremental workloads. Iceberg may be a good choice if you already have Hive-based tables. Engineers currently confront a challenging decision in selecting a table format — determining which features or benefits are critical for their use case. Ultimately, the decision matters on criteria such as:
- Feature-level comparison — let’s say you want to use the merge-on-read (MoR) tables for streaming-based writes. Is there a way to manage read performance, as MoR tables are not read-optimized?
- The complexity of implementation — how easy is it to migrate from an existing format or implement it from scratch? Are there any additional system dependencies that can lead to more costs in the future?
- Ecosystem — what compute engines currently support the table format? What type/level of support (read, write/ external, native tables) is it? How does it align with your current data stack?
- Community — the basis of a table format is its open nature. This also means abiding by an open standard driven by a diverse community.
There is also a hefty cost associated with evaluating the table formats. On top of that, there are also some new challenges as we learn from the experiences of operating lakehouses in production.
- newer workloads in a lakehouse architecture involve using multiple table formats
- organizations need data to be universal, meaning write once; query from any compute of choice
- teams want flexibility to choose from and cater to different use cases
This is what brings us to the next phase, i.e., interoperability.
Phase 2
With newer workloads and varied use cases, one thing has become evident — the table formats need to be interoperable. Until now, some of the ways to transition between open table formats relied on strategies that involved making full copies of data, which is slower and doubles the storage, or in-place migration that preserves the existing data files but might need write downtime, which isn’t favorable for specific use cases (such as streaming). There should also be a way to resolve format disparities across the existing three projects. More importantly, these table formats need a better way to coexist and not just be a one-way conversion thing.
Introducing Apache XTable (incubating)!
XTable is an open-source project that facilitates omnidirectional interoperability among various lakehouse table formats. This means it is not just limited to one-directional conversion but allows you to initiate conversion from any format to another without the need to copy or rewrite data. It is also important to note that XTable is not a new or separate format; instead, it offers abstractions and tools designed to translate metadata associated with the table formats. This new approach ensures seamless interaction and compatibility not just for the existing table formats but also provides an easy way for newer formats to adapt (more on this later).
The overall goal with XTable is that you can start with any table format of your choice, and if there is a specific requirement to switch to another one depending on the various factors discussed in Phase 1, you are free to do so.
XTable Sync: Working mechanism
If we step back and try to understand Hudi, Iceberg, and Delta Lake, fundamentally, they are similar. When the data is written to a distributed file system, these three formats have the same structure. They have a data layer, a set of Apache Parquet files, and a metadata layer on top of these data files, providing the necessary abstraction. Here is what it looks like at a high level.

The XTable sync process translates table metadata by leveraging the existing APIs of the table formats. It reads the current metadata for a source table and writes out metadata for one or more target table formats. The resulting metadata is stored under a dedicated directory in the base path of your table, such as _delta_log for Delta Lake, metadata for Iceberg, and .hoodie for Hudi. This enables your existing data to be interpreted as if it were originally written using Delta, Hudi, or Iceberg.
For instance, if you are using Spark to read data, you can just use:
spark.read.format("delta | hudi | iceberg").load("path/to/data")At a more granular level, XTable utilizes a standard model for table representation via lightweight abstraction layers. This unified model can interpret and translate various aspects, including schema, partitioning information, and file metadata, such as column-level statistics, row count, and size.
There are also additional interfaces for sources and targets that play a crucial role in translating to and from this model. These interfaces are designed to extend the current support of table formats to anything new that could be available in the future for some specific use case. For instance, let’s say you wanted to add a new target table format (e.g., Apache Paimon). To do so, you will just need to implement the TargetClient interface, and then you can integrate it into the OneTableClient class, which is responsible for managing the lifecycle of the sync process.

How to: Sync Process
To start using XTable, you will need to clone the GitHub repository in your environment and build the required jars from the source code. Here is how you can do so, using Maven. You can also follow the official documentation for a more detailed guide.
mvn clean packageAfter the build completes successfully, you should be able to use utilities-0.1.0-SNAPSHOT-bundled.jar to start your sync (or metadata translation).
Running the sync process involves creating the my_config.yaml file in the cloned XTable directory. Here is an example considering that the source is an Iceberg table and the target format is Hudi.
sourceFormat: ICEBERG
targetFormats:
- HUDI
datasets:
-
tableBasePath: file:///tmp/iceberg-dataset/people
tableDataPath: file:///tmp/iceberg-dataset/people/data
tableName: peopleFinally, you can run the following command to start the translation process.
java -jar utilities/target/utilities-0.1.0-SNAPSHOT-bundled.jar --datasetConfig my_config.yaml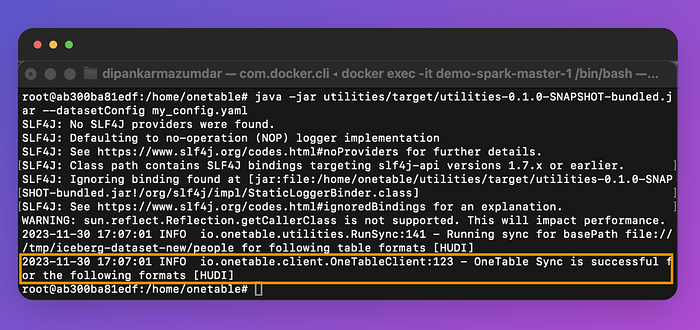
If successful, you should see the output shown in the snippet above. If you check your location path, you’ll find the essential metadata files with information such as schema, commit history, partitions, and column statistics.
Apache XTable Community
XTable was recently open-sourced under the Apache License, version 2.0. It operates independently (outside the 3 table formats repo), serving as a neutral space where various lakehouse table formats can collaborate effectively. Today, we have initial committers from Microsoft, Onehouse, and Google who incepted the project, and the next step is to incubate XTable into the Apache Software Foundation (proposal). Stay tuned!
While XTable is nascent, it has already made great strides in the community. Here are some vanity metrics from the launch and how it is progressing.

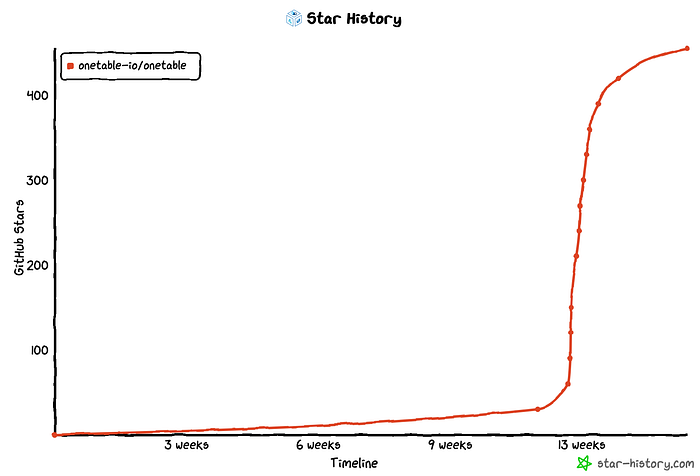
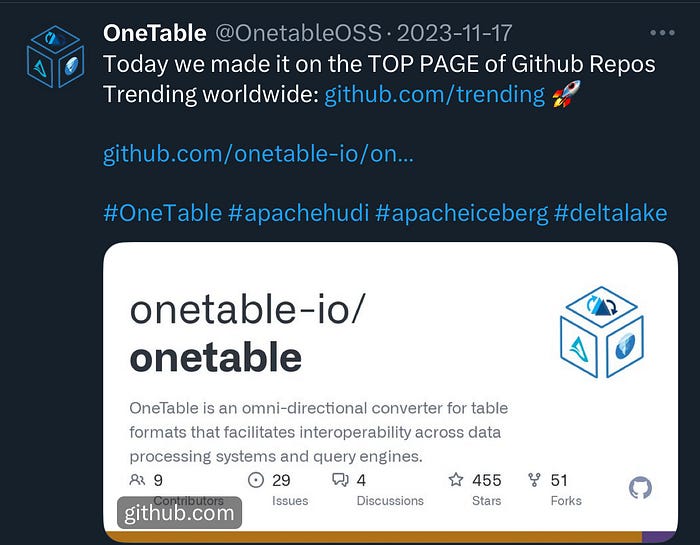
If you are interested in being a part of this novel community and contributing in any form, you are welcome to submit a pull request. You can also join the discussion board for any roadmap ideas or provide feedback that will help the project’s growth. Here is an insight into the future roadmap.
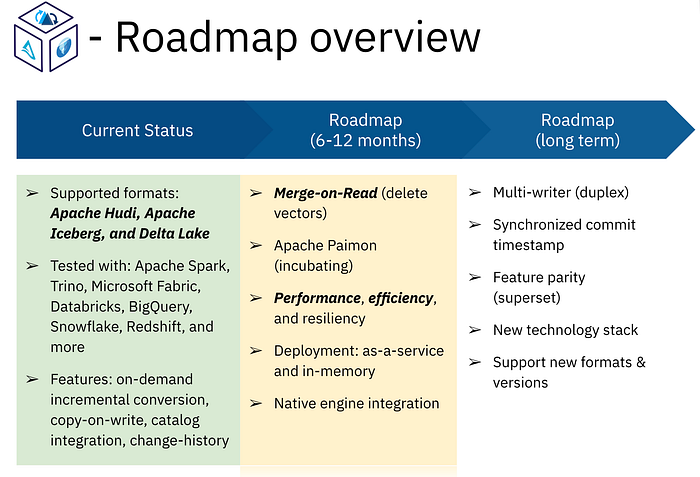
End Notes
XTable provides a new direction to deal with the tough decision of selecting and sticking with a table format. Now, while we started with the need for interoperability in this blog, it also brings back some critical questions, such as this one from the community.
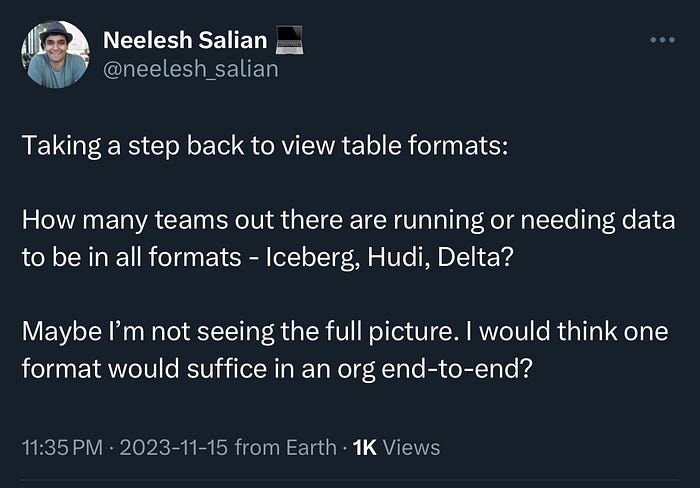
To provide some context, here are some aspects to consider as we move on to the next phase for lakehouses with ‘interoperability’ at the center.
- Compute vendor-favored table format: most compute engine vendors today are inclined towards a particular format (for better optimization, feature extensibility, etc.). This contradicts the initial idea of not locking in data to a specific vendor. In fact, this is one of the biggest motivations behind an open lakehouse architecture.
- Coexistence of table formats: most organizations adapting and operating lakehouses are known to have more than one table format in their architecture to get better data optimization capabilities offered by compute engines for a specific format. Additionally, different teams use different formats for use cases where they shine the most.
- Rollback/Migration: The decision to select a table format is correlated with another pressing question, i.e., what if there is a need to revert? Migration is usually a standard answer in this case, but it is very costly and involves tremendous engineering efforts/planning.
The idea behind this blog is to help understand the current state of lakehouse architecture and the need for interoperability. To address some of the pain points around this context, we present XTable, an abstraction for translating table format metadata. The following blog will focus on a specific use case and go through an end-to-end process.
If you want to hear more about XTable on the socials — (LinkedIn, Twitter), follow along.
Event on XTable
We also have an intro and live demo session coming up on December 14th (hosted by Onehouse). Register using the link below.
Note: OneTable is now an Apache Incubating project and referred to as “Apache XTable” instead. There are no changes other than that.
