Building a Streamlit app on a Lakehouse using Apache Iceberg & DuckDB
Developing full-stack data applications can be a massive overhead for data scientists or analysts who would need to spend a considerable amount of time building intuitive interfaces and managing the design aspects & infrastructure of such applications. This also removes their focus from building core data-specific features like ML models or visualizations. This is where low-code tools like Streamlit come into play, making it easy for these personas of developers to build and prototype data apps quickly.
There are various ways to consume data to build a Streamlit data application. I will take a slightly different approach in this blog by leveraging data directly from a Data Lakehouse.

Lakes, Lakehouse?
If you are new to lakehouse architecture or have been curious, here is a detailed blog. But in short, a lakehouse combines a data lake and a data warehouse’s capabilities. What this means is you now have the ability to manage data, such as evolve the schema of a table, and implement techniques like partitioning, data compaction, time-travel, etc., as in a warehouse, but the main difference is that your data isn’t stored in a proprietary format that is accessible only by the warehouse’s compute engine.
With a lakehouse approach, your data is stored in open files & table formats such as Apache Parquet and Apache Iceberg in a data lake storage like Amazon S3. This means you now have complete control of your data, and depending on your use case, you can leverage any compute engine and build analytical workloads on top of it. E.g., if you want to do low-latency SQL and BI, you can use a compute engine like Dremio Sonar, or if your use case is streaming, Apache Flink can be great.
Project
For this project, I wanted to build an exploratory data analysis (EDA) app using data from a lakehouse backed by the robust Apache Iceberg table format. We will use the Iceberg Python API, PyIceberg, as the primary compute to read Iceberg tables. PyIceberg allows us to interact with Apache Iceberg catalogs, read data & create tables.
The diagram below encapsulates a minimalistic lakehouse architecture used in this project.

The Stack:
- Data Lake: I use Amazon S3 as my data lake to store all the data and metadata files. My ingestion job will take care of inserting new data here in the future
- File format: Parquet, CSV files
- Table format & Catalog*: Apache Iceberg with AWS Glue
- Compute engine: Apache Spark (write to Iceberg table), PyIceberg (read Iceberg table), DuckDB (analysis)
- Application: Streamlit 🎈
- Libraries to install: streamlit, plotly, pyiceberg[glue, duckdb]
Our main advantage with using PyIceberg here is that we can scan an Iceberg table object and then return the object as — a Pandas dataframe, PyArrow table, or DuckDB table. This opens up the scope to quickly build downstream analytical applications using tools like Streamlit.
table.scan().to_pandas()
table.scan().to_arrow()
table.scan().to_duckdb()We will start with ingesting some data to our Iceberg table. PyIceberg, as of today, is limited to creating and reading tables. However, soon we should be able to write data using this library. To insert some records, I use Spark SQL, as shown below.
spark.sql(
"""CREATE TABLE IF NOT EXISTS glue.test.churn
(State STRING, Account_length STRING, Area_code STRING, International_plan STRING, Voicemail_plan STRING, Number_vmail_messages STRING, Total_day_minutes STRING, Total_day_calls STRING, Total_day_charge STRING, Total_eve_minutes STRING, Total_eve_calls STRING, Total_eve_charge STRING, Total_night_minutes STRING, Total_night_calls STRING, Total_night_charge STRING, Total_intl_minutes STRING, Total_intl_calls STRING, Total_intl_charge STRING, Customer_service_calls STRING, Churn STRING) USING iceberg"""
)
spark.sql(
"""CREATE OR REPLACE TEMPORARY VIEW churnview USING csv
OPTIONS (path "churndata.csv", header true)"""
)
spark.sql("INSERT INTO glue.test.churn SELECT * FROM churnview")If we query the data to confirm that the ingestion job ran successfully, we should see the records.
Now our goal is to read this table data from the Streamlit application and create our EDA app. We also allow users to input any other table name they might have in the same Iceberg catalog, and the app will display the records accordingly.
Here’s a code snippet that uses the PyIceberg API to interact with the Iceberg catalog (AWS Glue), load the churn table, and query the table using the scan() method. The scanned table object is then returned as a pandas dataframe using the to_pandas() method.
from pyiceberg.catalog import load_catalog
catalog = load_catalog("glue", **{"type": "glue"})
db = st.text_input('', 'test' + '.' + 'churn')
ice_table = catalog.load_table(db)
scan = ice_table.scan()
scan = scan.to_pandas()
st.write(scan)At this stage, we have managed to read an Iceberg table and write the object to the front end using the st.write() method in Streamlit. This is what our Iceberg table looks like in the app.
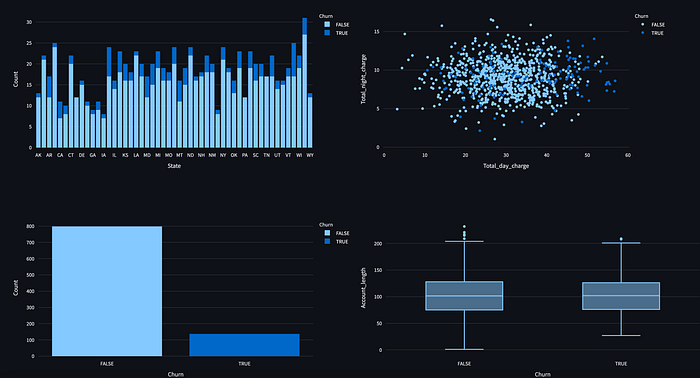
Based on this data, we want to do some exploratory data analysis and create four visualization objects as part of that.
churn_count = scan_new['Churn'].value_counts().reset_index()
churn_count.columns = ['Churn', 'Count']
col1, col2 = st.columns(2)
with col1:
state_churn_count = scan_new.groupby(['State', 'Churn']).size().reset_index()
state_churn_count.columns = ['State', 'Churn', 'Count']
fig1 = px.bar(state_churn_count, x='State', y='Count', color='Churn')
st.plotly_chart(fig1, use_container_width=True)
with col2:
fig2 = px.scatter(scan_new, x='Total_day_charge', y='Total_night_charge', color='Churn')
st.plotly_chart(fig2)
col3, col4 = st.columns(2)
with col3:
fig3 = px.bar(churn_count, x='Churn', y='Count', color='Churn')
st.plotly_chart(fig3, use_container_width=True)
with col4:
fig4 = px.box(scan_new, x='Churn', y='Account_length')
st.plotly_chart(fig4, use_container_width=True)Here’s the compiled app with the four charts.
In the last section, we want to allow users to analyze the Iceberg table further using a lightweight SQL database like DuckDB.
As discussed, the PyIceberg library allows us to easily convert an Iceberg table scan object to an in-memory DuckDB table. We can then execute any query using DuckDB based on an user input. Here’s a code snippet.
query = st.text_input('Query', 'SELECT * FROM churn LIMIT 5')
con = ice_table.scan().to_duckdb(table_name=table_name)
duck_val = con.execute(query).df()The interface along with an example query to analyze the average number of customer calls made per state can be seen below.

Here is our app in action.

That brings us to the end of this blog. The primary goal of this project was to show how we can build data applications directly on top of a lakehouse architecture using Apache Iceberg as the data lake table format. This enables us to take advantage of things such as:
- Schema evolution: what if our dataset changes with business needs? For e.g., adding some new features to the table. With Iceberg, there are no side effects or zombie data.
- Time travel & rollbacks: what if some ETL job leads to a ‘data incident’? We can quickly fix problems with Iceberg by resetting the table to a good state.
- Performance: Iceberg is built for datasets of any size. In fact, Iceberg has proven to be performant with large-scale tables. Iceberg’s architectural design (metadata) & techniques like pruning, compaction, and Z-ordering helps greatly with query speed.
Notes:
- This application is in a rudimentary form and will evolve with time as we add more data and capabilities.
- Performance wasn’t evaluated as part of this exercise as the idea was to show how to build data apps on a single node, i.e., a user laptop.
- *Catalog supported as of now with the PyIceberg library are Glue, Hive or REST.
- The app isn’t deployed publicly. I plan to add more capabilities soon for users to have a way to play around with Iceberg tables.
Here’s the code repository:
Reach out for any questions or suggestions.
